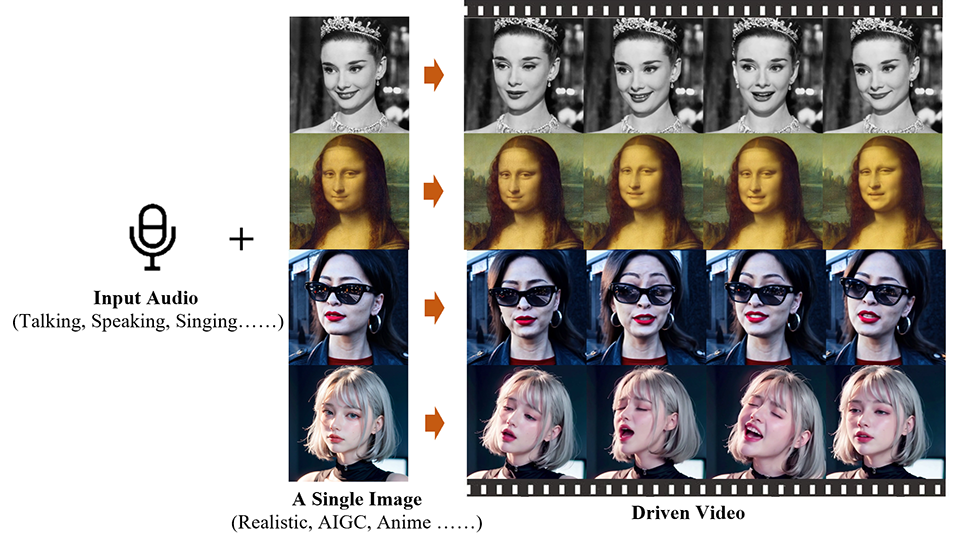
Chinese engineers at the Alibaba Group Institute of Intelligent Computing have developed an artificial intelligence app called Emote Portrait Live that can animate a still photo of a face and sync it with an audio track.
The technology behind this is based on the generative capabilities of diffusion models (mathematical models used to describe how things propagate or diffuse over time), which can directly synthesize videos of character heads from an image provided and any audio clips. This process avoids the need for complex preprocessing or intermediate renderings, thus simplifying the creation of talking head videos.
The challenge lies in capturing the nuances and diversity of human facial movements during video synthesis. Traditional methods simplify this by imposing constraints on the final video output, such as using 3D models to constrain facial keypoints or extracting head movement sequences from base videos to guide overall motion. However, these limitations can limit the naturalness and richness of the resulting facial expressions.
Not without challenges
The research team's goal is to develop a talking head framework that can capture a wide range of realistic facial expressions, including subtle microexpressions, and enable natural head movements.
However, integrating audio with diffusion models presents its own challenges due to the ambiguous relationship between audio and facial expressions. This can cause jitter in the videos produced by the model, including facial distortions or jitter between video frames. To overcome this, the researchers included stable control mechanisms in their model, specifically a speed controller and a frontal region controller, to improve stability during the generation process.
Despite the potential of this technology, there are certain drawbacks. The process takes longer than methods that do not use diffusion models. Additionally, since there are no explicit control cues to guide the character's movement, the model may unintentionally generate other body parts, such as hands, resulting in artifacts in the video.
The group has published an article about their work on the arXiv preprint server, and this website hosts a number of other videos showcasing the possibilities of Emote Portrait Live, including clips of Joaquin Phoenix (as The Joker), Leonardo DiCaprio, and Audrey Hepburn.
You can watch Mona Lisa recite Rosalind's monologue from Shakespeare's play. To your tasteAct 3, Scene 2, below.





