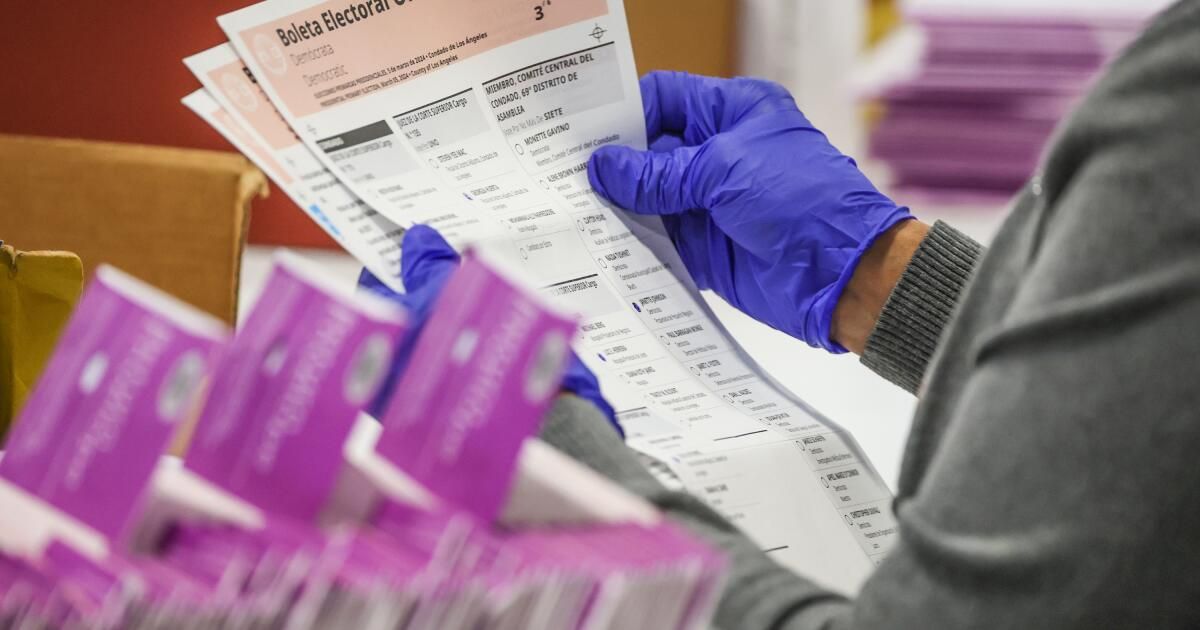
When Angelenos voted in this year's California primary, one important group was left out: speakers of indigenous Latin American languages like Zapotec and K'iche', who are not among the 19 languages in which Los Angeles County provides election materials. It's a particularly troubling oversight in Los Angeles. Our city has the largest population of Native American and indigenous peoples in any city in the United States, and its omission has serious implications for inclusion.
Section 203 of the Federal Voting Rights Act requires counties to provide election materials in the language of a linguistic minority who is not sufficiently proficient in English to vote without assistance. That group must be greater than 10,000 people or represent at least 5% of a county's total eligible voting population. California also requires personalized ballots, at a lower threshold than federal law: Counties here have to translate the ballot for any single-language minority who lacks English proficiency if they make up at least 3% of residents in voting age of an electoral district.
To determine compliance with these laws, local and federal authorities analyze census data collected every 10 years. But the government has long struggled to provide an accurate count of Latin Americans.
Until this year, when the federal government changed the policy after years of debate, the census asked respondents two different questions about whether they were of Latino/Hispanic origin and what their race and ethnicity were. This approach confused some Americans who see their Latino or Hispanic identity as their ethnicity, not something distinct from it. The decision to combine those questions follows another change that was intended to make the count more accurate: Since 2020, the census has included free-response lines so people can write in a specific origin, such as German or Nigerian, and count up six. different origins per respondent, comparing them with broader racial categories, such as black and white.
Allowing such detailed responses seemed to make the data collection more complete, growing the Latin American indigenous population recorded by 390.4% between 2010 and 2020. Still, many scholars, including us, expect that the census still woefully underestimates the population of the indigenous peoples of Central and South America.
More specifically, because it tracks language in much less detail than race and ethnicity, it is not a reliable data point for translations. Consider: Although census data documents 22,024 people of Latin American descent in Los Angeles County who speak a language other than English or Spanish (over the Section 203 threshold of 10,000 voters) does not identify what those languages are.
During the COVID-19 pandemic, the nonprofit Comunidades Indígenas en Liderazgo (Indigenous Communities in Leadership), or CIELO, collected that missing data. Surveyed Latin American indigenous communities in Los Angeles and created a map of its linguistic diversity, showing a concentration of Zapotec speakers of voting age in the Pico-Union and Koreatown areas.
When we overlaid the CIELO map on a Los Angeles county enclosure map, we identify approximately 36 districts, generally between Wilshire and West Washington boulevards and from South Fairfax Avenue to South Hoover Street, with high concentrations of Zapotec speakers. Our data suggests that these speakers made up more than 12% of adults in those districts, far exceeding the state requirement of 3%. But because official census numbers don't reflect this level of detail, these Angelenos can't vote in their primary language.
The impact of this gap extends far beyond voting. For example, the indigenous peoples of Mexico and Guatemala was missing essential information about COVID-19 in their native languages during the pandemic, prompting CIELO and other groups to provide translations. Similarly, during Forest fire seasons, translated information on evacuation areas, shelters, and air quality has been scarce. While other nonprofit groups, such as the Mixtec/Indigenous Community Organizing Project, have stepped up to provide translations, a fragmented reliance on volunteers cannot guarantee access to everyone who needs these resources.
As we approach the conclusion of the design phase For the 2030 census, we urge the Census Bureau to actively collaborate with indigenous Latin American stakeholders to ensure an accurate count and capture the linguistic diversity within these communities. These collaborations should ensure that respondents understand census updates and are prepared to provide accurate responses. They should also explore avenues for collecting more detailed linguistic information. By ensuring that all voices are heard and taken into account, we build a more inclusive democracy that reflects the rich diversity of our city.
Jessica Cobian is a senior fellow and Sebastian Cazares is a graduate fellow at the UCLA Voting Rights Project. Heidy Melchor is founder and alumni advisor of the UCLA Oaxacan Student Group.